
解答
CHAPTER 4
006
SQL文(クエリ)
SELECT birthday, COUNT(*) AS users
FROM impress_sweets.customers
WHERE birthday IS NOT NULL
GROUP BY birthday
HAVING users > 1
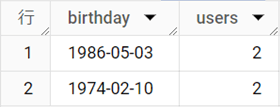
結果テーブル
解説
[birthday]でグループ化して「COUNT(*)」でレコード数を調べます。もちろん「COUNT(DISTINCT customer_id)」でも正解ですが、1レコードが1ユーザーに対応しているテーブルであれば、「COUNT(*)」でも結果は同じです。
007
SQL文(クエリ)
SELECT user_id, count(*) AS pageviews
FROM impress_sweets.web_log
WHERE media = "email" AND user_id IS NOT NULL AND event_name = "page_view"
GROUP BY user_id
HAVING pageviews >= 10
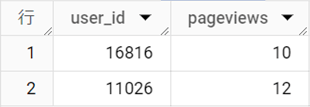
結果テーブル
解説
[media]を「email」に絞り込むには、3行目のようにWHERE句を使います。表示するレコードを「pageviews >= 10」を利用して絞り込むには、5行目のようにHAVING句を使います。
別解として、以下の通り[event_name]が "page_view"に等しいときだけ1を返すIF文を利用し、SUM関数でその数を数えて[pageviews]とする方法があります。
SQL文(クエリ)
SELECT user_id, SUM(IF(event_name="page_view",1,0)) AS pageviews
FROM impress_sweets.web_log
WHERE media = "email" AND user_id IS NOT NULL
GROUP BY user_id
HAVING pageviews >= 10
結果テーブル
008
SQL文(クエリ)
SELECT prefecture, COUNT(DISTINCT customer_id) AS users
FROM impress_sweets.customers
WHERE is_premium IS TRUE
GROUP BY prefecture
ORDER BY 2 DESC
LIMIT 1
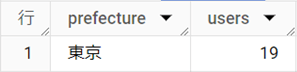
結果テーブル
解説
[prefecture]フィールドでグループ化する必要があるので、SELECT句とGROUP BY句に[prefecture]を指定します。また、ユニークな顧客数(customer_id)は「COUNT(DISTINCT customer_id)」で調べます。絞り込み条件の「プレミアム顧客に一致」は、3行目のWHERE句としてFROM句に続けて記述します。
最終行で「LIMIT 1」と記述していますが、まずは並べ替えが正しいかを確認するためにLIMIT句なしで実行し、その後に付与すると安全です。
009
SQL文(クエリ)
SELECT user_pseudo_id
, COUNT(DISTINCT ga_session_number) AS number_of_visits
FROM impress_sweets.web_log
GROUP BY user_pseudo_id
ORDER BY number_of_visits DESC
LIMIT 3
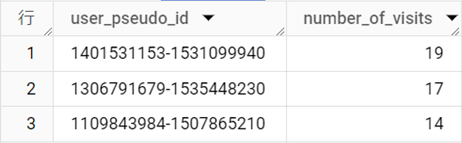
結果テーブル
解説
[user_pseudo_id]でグループ化する必要があることは容易に理解できると思います。集計は[ga_session_number]という訪問回数が記録された整数型のフィールドに、固有の値がいくつあるか?を行います。例えば、「1」と「2」が記録された[user_pseudo_id]は2、「12」「13」「14」が記録された[user_pseudo_id]は3となります。
別解として以下も挙げておきます。
SELECT user_pseudo_id
, MAX(ga_session_number) - MIN(ga_session_number) +1 AS number_of_visits
FROM impress_sweets.web_log
GROUP BY user_pseudo_id
ORDER BY number_of_visits DESC
LIMIT 3
別解の考え方は[user_pseudo_id]ごとに最大の[ga_session_number]から、最小の[ga_session_number]を差し引いて1をプラスする、というものです。例えば最大が6、最小が2のユーザーは「2回目訪問から6回目訪問」の合計5回の訪問を行ったことになるという考え方です。
ただし、実際のGA4では、まれに[user_pseudo_id]別の[ga_session_number]が飛んでいる場合があります。例えば、ある[user_pseudo_id]の[ga_session_id]として、「1」「2」「4」「5」が記録されていて、記録されていてしかるべき「3」が記録されていない場合があります。そのような場合、上記の解と別解では異なった結果となるので注意してください。
010
SQL文(クエリ)
SELECT
CASE
WHEN cost BETWEEN 0 AND 299 THEN "1.価格帯 0-299"
WHEN cost BETWEEN 300 AND 599 THEN "2.価格帯 300-599"
WHEN cost BETWEEN 600 AND 899 THEN "3.価格帯 600-899"
WHEN cost BETWEEN 900 AND 1199 THEN "4.価格帯 900-1199"
ELSE "5.その他の価格帯"
END AS cost_range
, COUNT(DISTINCT product_id) AS items
FROM impress_sweets.products
GROUP BY cost_range
ORDER BY 1
結果テーブル
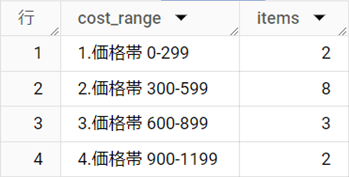
解説
上記のCASE文では、3~6行目のWHEN句で指定した条件のどこかに、すべての[product_id]が当てはまります。もし[products]テーブルに原価(cost)が1,200円以上の[product_id]が存在した場合、「5.その他の価格帯」に分類されます。
どのような値が存在するか分からない場合には、ELSE句でどのWHEN句にも当てはまらなかった場合の分類を指定するのが望ましいです。そうしなかった場合、どのWHEN句にも当てはまらない値は「null」に分類されます。
なお、この問題では、仕入金額を[cost_range]という4つのカテゴリに分類し、そのカテゴリに該当する[product]などの数(商品アイテム数)を取得しました。こうした表を「度数分布表」と呼び、統計学ではカテゴリのことを「階級」、該当する数を「度数」といいます。
階級が金額や個数などの数値で表せる大小関係がある「量的変数」に基づく場合、その中央値を「階級値」と呼びます。例えば、「0円以上300円未満」の階級の階級値は150円です。
度数分布表の階級が量的変数に基づく場合は、通常、階級値の小さい順に並べるのが作法です。階級をCASE文で分類するとき、「1. 価格帯 0 -299」のように先頭に数字を入れることで、ORDER BY句で並べ替えができるように工夫しています。
また、度数分布表をBIツールに読み込み、度数を面積に対応させ、棒状のグラフを棒と棒の隙間なく視覚化したグラフを「ヒストグラム」と呼びます。この問題・解答をもって、SQLで度数分布表の作成ができること、そのデータをBIツールに読み込めば容易にヒストグラムを作成できることを理解してもらえるかと思います。



