
解答
CHAPTER 7
021
SQL文(クエリ)
SELECT product_id
, CAST(ROUND(SUM(revenue), -3) AS INT64)
AS sum_revenue
FROM impress_sweets.sales
GROUP BY product_id
ORDER BY 2 DESC
LIMIT 5
結果テーブル
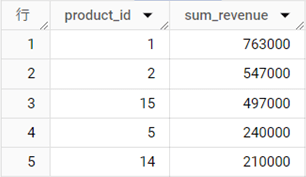
解説
2行目がポイントです。SUM関数で[revenue]を合計し、ROUND関数で百の位で四捨五入します。戻り値はFLOAT64型となり、小数点以下第一位に「0」が残ってしまため、CAST関数で整数にデータ型を変換しています。
022
SQL文(クエリ)
SELECT CONCAT(customer_name, keisho) AS name_with_keisho
, birthday
, age
FROM (
SELECT customer_name, birthday
, DATE_DIFF(DATE("2023-12-31"), birthday, YEAR) AS age
, IF(DATE_DIFF(DATE("2023-12-31"), birthday, YEAR) >= 50
, "さま", "さん") AS keisho
FROM impress_sweets.customers
WHERE birthday IS NOT NULL
)
WHERE customer_name LIKE ANY ("%米田%", "%鬼木%")
ORDER BY birthday
結果テーブル
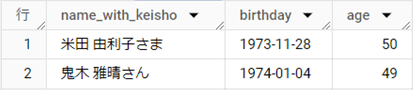
解説
DATE_DIFF関数とCONCAT関数の2つを使います。DATE_DIFF関数では、満年齢を決める2023年12月31日から、誕生日を引いた結果を「年」で表示することで、年齢を取得しています。
7~8行目のIF文では「年齢が50以上か、そうでないか」を条件に、「さま」か「さん」かを[keisho]として取り出します。最後に、メインのクエリで[customer_name]と[keisho]を連結して[name_with_keisyo]とし、[birthday][age]とともに出力しています。
など、別解として、12行目のWHERE句は正規表現関数(REGEXP_CONTAINS)を利用して以下としてもよいでしょう。
WHERE REGEXP_CONTAINS(customer_name, "米田|鬼木") IS TRUE
023
SQL文(クエリ)
SELECT
DATETIME_TRUNC(
DATETIME(
TIMESTAMP_MICROS(event_timestamp),"+9")
, MONTH) AS year_month
, SUM(IF(event_name= "page_view",1,NULL)) AS pageviews
FROM impress_sweets.web_log
GROUP BY year_month
ORDER BY 2 DESC
LIMIT 3
結果テーブル
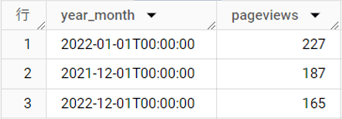
解説
イベント発生時刻である[event_timestamp]カラムは、マイクロ秒のUNIX時(16桁の整数)で表現されています。それを4行目のTIMESTAMP_MICROS関数を利用してTIMESTAMP型に変換したうえで、3行目のDATETIME関数で+9時間の時差調整し、日本時刻にしています。さらに、2行目のDATETIME_TRUNC関数で「年月」で丸め、[year_month]フィールドを作成しています。
6行目では、[event_name]が"page_view"に等しい場合に1を返して指標化するとともに、合計で集計してpageviewsを求め、8行目でyear_monthでグループ化しています。
なお、[event_datetime]カラムを、時差調整済のDATETIME関数に変更したあとは、FORMAT_DATETIME関数を使って「年月」で丸めたり、pageviewsを求めるのにCOUNTIF関数を利用する以下の別解も考えられます。
SELECT
FORMAT_DATETIME("%Y-%m",
DATETIME(
TIMESTAMP_MICROS(event_timestamp),"+9")
) AS year_month
, COUNTIF(event_name= "page_view") AS pageviews
FROM impress_sweets.web_log
GROUP BY year_month
ORDER BY 2 DESC
LIMIT 3
年月日を「丸める」ケースは非常に多く、このような問題を解くと理解が深まるのではないかと思います。このテクニックは日ごとに丸めてグループ化する、曜日ごとに丸めてグループ化するなど、広く応用が利きます。
024
SQL文(クエリ)
SELECT customer_name, first_name
FROM (
SELECT customer_name
, REGEXP_EXTRACT(customer_name, r"^.川\s(..子)$") AS first_name
FROM impress_sweets.customers
WHERE gender = 2
)
WHERE first_name IS NOT NULL
結果テーブル
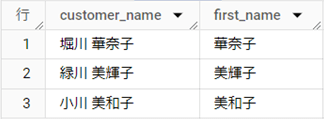
解説
正規表現を使う場合は、REGEXP_EXTRACT関数を利用し、[customer_name]フィールドから該当する文字列を直接[first_name]として取得します。
上記SQL文で利用している正規表現は以下の通りです。
- ^ 次の文字で始まる
- . 任意の1文字
- \s 半角スペース
- () グループ。囲まれた部分に該当する文字列を取得する
- $ 直前の文字で終わる
前ページのSQL文の4行目を丁寧に読み解くと、題意に沿った正規表現が記述されていることが理解できると思います。
なお、正規表現を利用しない場合、WHERE句でLIKE演算子を使って、姓が「○川」、名が「○○子」のレコードに絞り込みます。以下が別解です。
[name]フィールドに格納されている氏名は半角スペースで区切られていることが分かっているので、STRPOS関数を使って半角スペースが出現する位置を取得し、SUBSTR関数でその位置を利用して姓名を別個に取り出します。
SELECT customer_name, first_name
FROM (
SELECT customer_name
, SUBSTR(customer_name, 1, STRPOS(customer_name, " ") - 1) AS family_name
, SUBSTR(customer_name, STRPOS(customer_name, " ") + 1) AS first_name
FROM impress_sweets.customers
WHERE gender = 2
)
WHERE family_name LIKE ("_川")
AND first_name LIKE ("__子")
025
SQL文(クエリ)
WITH master AS (
SELECT user_id, MIN(DATETIME_TRUNC(date_time, DAY)) AS first_purchase_date
FROM impress_sweets.sales
GROUP BY user_id
), master2 AS (
SELECT *, DATE_ADD(first_purchase_date, INTERVAL 30 DAY) AS thirty_days_lator
FROM master
)
SELECT user_id, COUNT(DISTINCT order_id) AS orders, SUM(quantity) AS sum_qty, SUM(revenue) AS sum_rev
FROM (
SELECT user_id, date_time, order_id, quantity, revenue, first_purchase_date, thirty_days_lator
FROM impress_sweets.sales
LEFT JOIN master2
USING (user_id)
)
WHERE date_time BETWEEN first_purchase_date AND thirty_days_lator
GROUP BY user_id
HAVING COUNT(DISTINCT order_id) > 1
ORDER BY sum_rev DESC
LIMIT 3
結果テーブル

解説
WITH句を2つ数珠つなぎで使っています。最初のWITH句は、[user_id]ごとに初回購入日を取得しています。その際、日付時刻型のフィールドである[date_time]をDATETIME_TRUNC関数で「日」に丸めています。
最初のWITH句でユーザーごとの初回購入日が取得できたので、2つ目のWITH句では、初回購入日から30日後の日付のカラムを追加しています。
本体のクエリはサブクエリを使っています。サブクエリでは[sales]テーブルと2つ目のWITH句の戻り値である[master2]を左外部結合しています。そして、[sales]テーブルからは[user_id][date_time][order_id][quantity][revenue]の5つのフィールドを、[master2]仮想テーブルからは[first_purchase_date][one_month_lator]をそれぞれ取得しています。
外側の結果テーブルを取得する最終的なクエリでは、ユーザー(user_id)ごとに、注文数(order_idのユニークカウント)、数量(quantityの合計)、売上(revenueの合計)を集計しています。その際、題意に合うように、次の2つの絞り込みをしています。
WHERE句では、注文時刻(date_tiem)が、初回購入日(first_purchase_date)とその30日後(thirty_days_lator)の間であること、HAVING句では、注文回数(COUNT(DISTINCT order_id))が1よりも大きいことです。最後に、並び順を売上合計の降順にし、最初の3行だけ取得しています。



