
解答
CHAPTER 8
026
SQL文(クエリ)
WITH master AS (
SELECT user_pseudo_id, ga_session_number, event_name, page_location
,LEAD(event_name) OVER(PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp) AS next_event
,LEAD(page_location) OVER(PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp) AS next_page
FROM impress_sweets.web_log
)
SELECT *, scrolls/pageviews AS scroll_rate
FROM(
SELECT page_location, SUM(pageview) AS pageviews, SUM(scroll) AS scrolls
FROM(
SELECT *
, IF(event_name="page_view",1,NULL) AS pageview
, IF(page_location = next_page AND event_name="page_view" AND next_event = "scroll",1,NULL) AS scroll
FROM master
) GROUP BY page_location
)
WHERE pageviews >= 100
ORDER BY scroll_rate DESC
結果テーブル
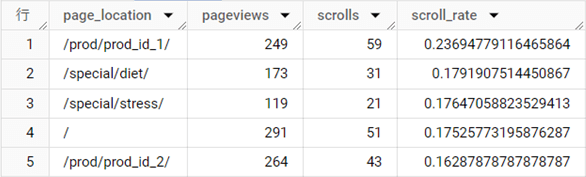
解説
WITH句の仮想テーブルでは、[user_pseudo_id][ ga_session_number][ event_name][ page_location]とともに、ウィンドウ関数の1つであるLEAD関数を使って[event_timestamp]順にレコードを並べた場合の、次の行の[event_name]を[next_event]として、[page_location]を[next_page]として取得しています。
本体のSQLでは「event_nameがpage_viewに等しい」という条件で1を立ててページビューを記録しています。また、「同じページで、直後にスクロールが発生した」という条件を満たすために
- page_locationとnext_pageが等しく
- event_nameが"page_view"で、next_eventが"scroll"
あとは、page_locationでグループ化して、ページビューも、スクロールも合計で集計すると解を導けます。LEAD関数で次の行の値を、自分の行に持ってくることに気づくことがこの問題を解く最大の関門だったのではないかと思います。
027
SQL文(クエリ)
SELECT product_category, product_name, cost
, RANK() OVER (PARTITION BY product_category ORDER BY cost DESC) AS cost_rank
FROM impress_sweets.products
QUALIFY cost_rank <= 3
ORDER BY 1, 4
結果テーブル
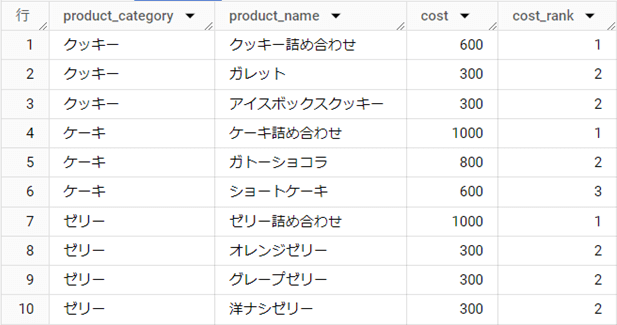
解説
RANK関数のパーティションは「○○ごとの」と考えます。よって、PARTITION BY句には[product_category]を指定します。[cost]を高い順に並べ替えるため、ORDER BY句のオプションは「DESC」です。
[cost_rank]を3以内に絞り込むために最終行でQUALIFY句を利用しています。もし、QUALIFY句を思いつかない、正確性に自信がないので使いたくないなどで、QUALIFY句を使わない場合の別解は以下となります。
WHERE句を使う場合には、一旦内側をサブクエリにして、WHERE句は外側のクエリの一部として利用する必要があります。
SELECT * FROM (
SELECT product_category, product_name, cost
, RANK() OVER (PARTITION BY product_category
ORDER BY cost DESC) AS cost_rank
FROM impress_sweets.products)
WHERE cost_rank <= 3
ORDER BY 1, 4
028
SQL文(クエリ)
WITH master AS (
SELECT FORMAT_DATETIME("%Y-%m", date_time)
AS year_month
, product_id
, SUM(revenue) AS sum_rev
FROM impress_sweets.sales
GROUP BY year_month, product_id
)
SELECT
year_month, product_id
, sum_rev / SUM(sum_rev) OVER (PARTITION BY year_month
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS monthly_revenue_share
FROM master
QUALIFY monthly_revenue_share > 0.4
ORDER BY 3 DESC
結果テーブル
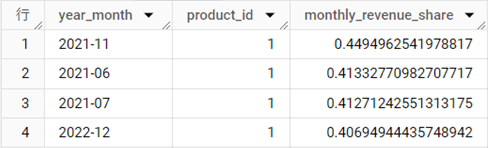
解説
WITH句で月別・商品ID別の販売金額合計を仮想テーブルとして作成しています。メインのクエリでは、商品別の販売金額シェア(monthly_revenue_share)を求めるために、商品別の販売金額をその月の販売金額合計で割った結果を取得しています。月の販売金額を合計するために、PARTITION BY句の後ろに「year_month」がきていること、WINDOWフレーム句でフレームをパーティション全体に広げていることに注目してください。
また、QUALIFY句を利用して月内の販売金額シェアが40%を超える商品だけに絞り込んで表示しています。
029
SQL文(クエリ)
SELECT first_purchase_product
, COUNT(DISTINCT user_id) AS number_of_users
FROM (
SELECT user_id
, MAX(first_product) AS first_purchase_product
FROM (
SELECT user_id, product_id
, FIRST_VALUE(product_id) OVER (PARTITION BY user_id
ORDER BY date_time, product_id) AS first_product
FROM impress_sweets.sales
)
GROUP BY user_id
)
GROUP BY first_purchase_product
ORDER BY 2 DESC
LIMIT 5
結果テーブル
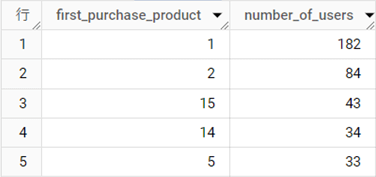
解説
いちばん内側のクエリ(7~10行目)のポイントは、「顧客ごとに購入日時が同じ場合、商品ID(product_id)が小さい商品を初回に購入したと見なす」処理です。
[sales]テーブルには1人の顧客(user_id)について、同一の日時(date_time)を持つレコードが複数存在する場合があります。それは1 つの注文(order_id)で、複数の商品が同時に購入されたことを表します。
その場合、もっとも商品IDの小さい商品をパーティションのいちばん上に並べ替える必要があります(9行目)。OVER句にあるORDER BY句に[date_time]と[product_id]を記述することにより、まず購入日時の古い順(小さい順)に並べ、さらに同一パーティション内に同一の購入日時があれば、商品IDを小さい順に並べる処理をしています。
1つ外側のクエリでは、1人の顧客に対して複数レコードが存在する状態を解消するために、[user_id]をグループ化し、MAX関数で[first_product]を集計しています。[first_product]は1 ユーザーに対して1 種類の値しか存在しないので、MAX関数、MIN関数のどちらでも同じ戻り値となりますが、ここではMAX関数を利用しています。
また、最終的な結果テーブルがより分かりやすくなるよう、フィールド名を[first_purchase_product]に変更しました。もっとも外側のクエリでは[first_purchase_product]ごとに、その商品を最初に購入した顧客が何人いるのかを集計し、顧客数の多い順に並べ替えて、5人に絞り込んでいます。
030
SQL文(クエリ)
WITH master AS (
SELECT user_pseudo_id, ga_session_number
, FIRST_VALUE(page_location) OVER (PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp) AS l_page
, LAST_VALUE(page_location) OVER (PARTITION BY user_pseudo_id, ga_session_number ORDER BY event_timestamp ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS e_page
FROM impress_sweets.web_log
WHERE event_name = "page_view"
)
SELECT
concat(l_page, " -> ", e_page) AS landing_and_exit
, COUNT(*) AS session
FROM (
SELECT user_pseudo_id, ga_session_number, MAX(l_page) AS l_page, MAX(e_page) AS e_page
FROM master
GROUP BY user_pseudo_id, ga_session_number
HAVING COUNT(*) > 1
)
GROUP BY l_page, e_page
ORDER BY 2 DESC
LIMIT 5
結果テーブル
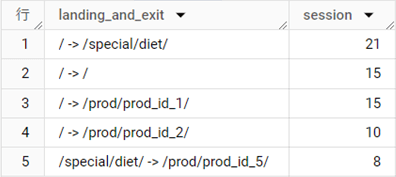
解説
WITH句では、ランディングページと離脱ページを取得しています。セッションは[ga_session_id]と[ga_session_number]の組み合わせで決まるので、その2つのフィールドをパーティションにしたうえで、パーティション中のレコードを[date_time]の昇順に並べ替えます。WHERE句で[event_name]は、"page_view"だけに絞り込んでおきます。
パーティションの上端の[page]の値をFIRST_VALUE関数で取り出してランディングページ(l_page)とし、パーティションの下端の[page]の値をLAST_VALUE関数で取り出して離脱ページ(e_page)として取得します。
WINDOWフレーム句を省略した場合、パーティションの上端から現在のレコードまでを示す「ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW」が適用されるため、ランディングページを取り出すためのFIRST_VALUE関数では省略しています。
一方、離脱ページを取り出すためのLAST_VALUE関数では、パーティションの下端の値が必要です。WINDOWフレーム句として「ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING」を記述して、明示的にLAST_VALUE関数がパーティションの下端の値を取得できるようにしています。
メインのクエリでは、内側のクエリで[cid]と[session_count]をグループ化し、MAX関数で[l_page]と[e_page]を集計しています。
そのうえで、[user_pseudo_id]と[ga_session_number]でグループ化したときのレコード数がセッション中のページビュー数を示すので、HAVING句で「1より大きい」条件で絞り込んでいます。
もっとも外側のクエリは、文字列を連結するCONCAT関数で「(ランディングページ) →( 出口ページ)」という文字列を生成して、レコード数を集計しています。すでに内側のクエリで[cid]と[session_count]でグループ化されており、各レコードは「セッション」を表すため、レコード数をカウントすれば、セッション数を取り出せるというわけです。



