
本コンテンツでは、無料で使えるBIツール「Googleデータポータル」(旧:Googleデータスタジオ)の使い方を連載形式で解説していきます。
連載の記事一覧
中間データ(キャッシュ)を生成して高速化
連載第27回となる今回は、Googleデータポータルで利用できる「データの抽出」機能について解説します。
ここ数回の連載では、データポータルの機能の中でも「インタラクション」(相互作用)に関するものを集中的に紹介してきました。企業がDX(デジタルトランスフォーメーション)を推進するうえでもっとも必要な要素は、社内の多くの人がデータを触る習慣(理由)を作るをことに尽きます。
そこで、ユーザー自身がダッシュボードを操作できるインタラクションの実装が重要になるのですが、取り扱うデータが大量になってくると、操作してから反応が返ってくるまでの時間が長くなるという問題が発生しがちです。
すると、「表示に時間がかかるから面倒くさい」といって、結局ダッシュボードを触らなくなってしまう人が出てきます。
1つ例を紹介しましょう。以下はデータポータルの実際のダッシュボードで、筆者が勤務する株式会社クレストの関連店舗に設置した交通量計測センサーのデータを表示したものになります。
このダッシュボードの元データは、「Google BigQuery」というデータベースに保管されています。通常の方法であれば、画面を表示するたびに、以下の図に示したような工程が毎回発生します。
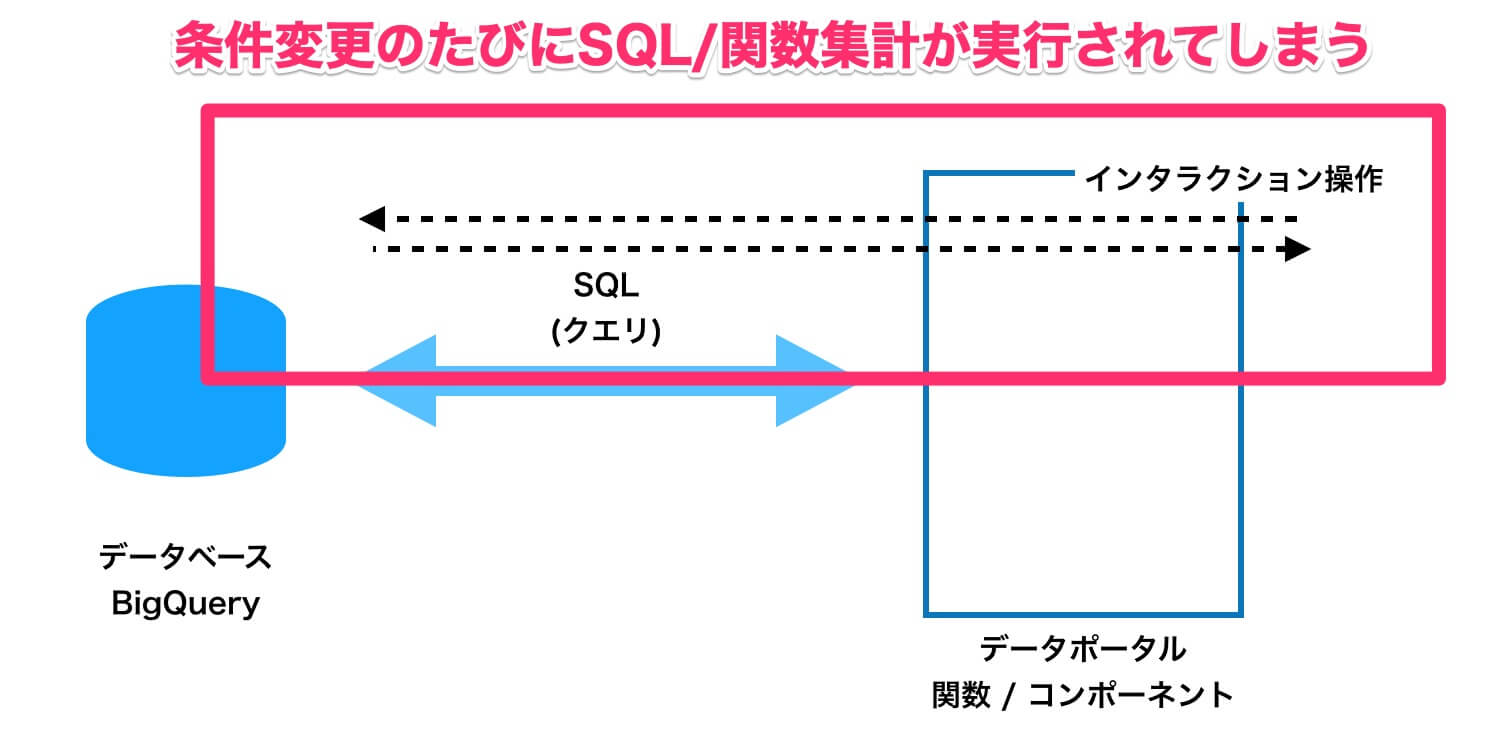
BigQueryに対してクエリ(SQLによる問い合わせ)を実行してデータを取得し、それをデータポータの関数で再計算(集計)するという通信や処理が、ダッシュボードを表示・更新するたびに発生します。
こういった通信や処理の繰り返しが、画面の読み込みが遅い(動作が重い)原因になってしまいます。
しかし、データポータルの「データの抽出」機能を使うと、毎回発生していたデータベースへの問い合わせをやめ、中間データを経由して表示する形で設計変更することができます。図に表すと、以下のようになります。
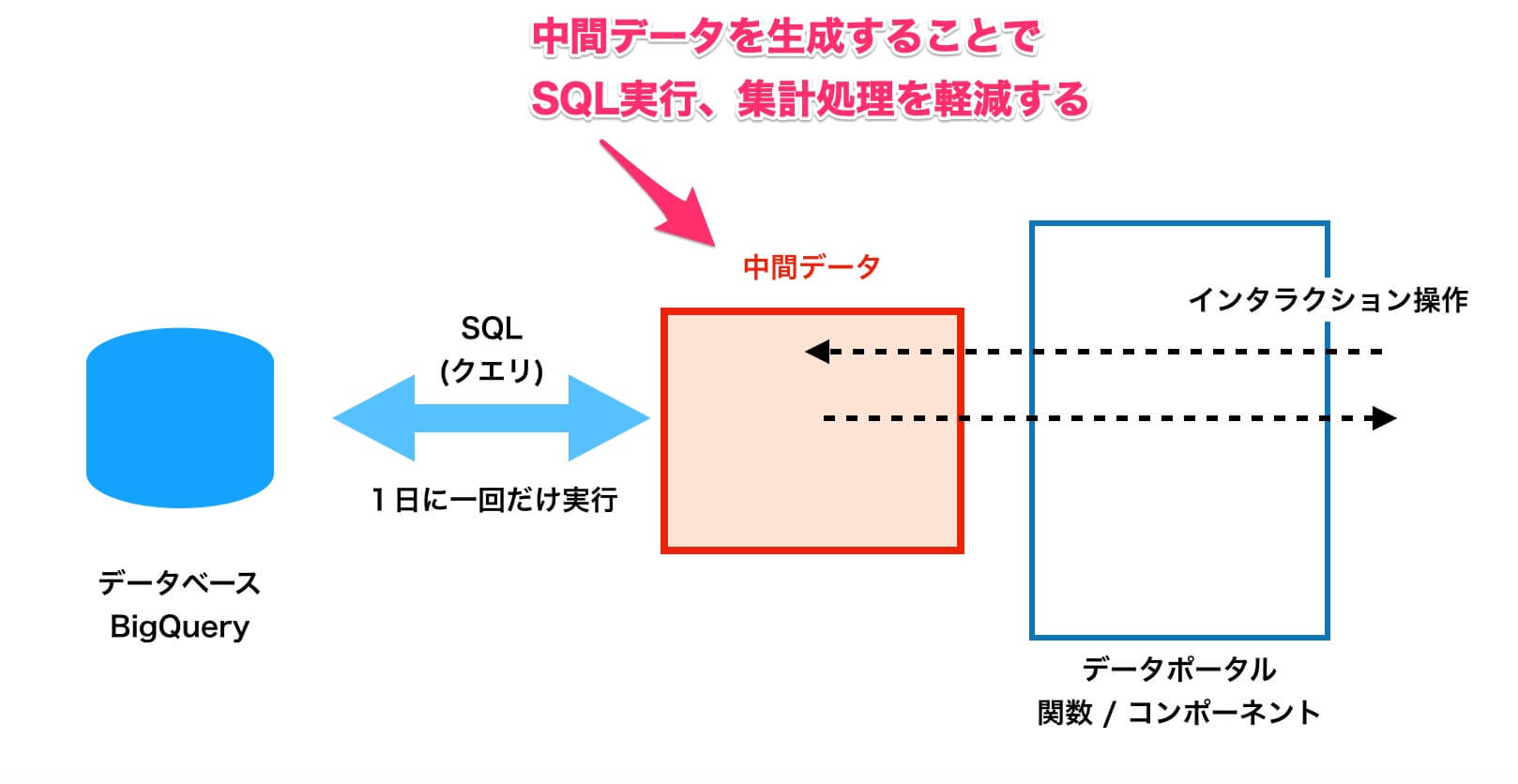
BigQueryから抽出したデータを中間データとして生成することで、ダッシュボードを表示・更新するときの速度が大幅に向上します。
こうした中間データは、「キャッシュ」と表現したほうがわかりやすいかもしれません。例えば、Webブラウザーは一度表示したサイトのデータをキャッシュとして保持し、そのサイトに再度アクセスしたときの表示を高速化することができますが、それと同じものです。
実は、先ほど例として挙げたダッシュボードも、「データの抽出」機能によって中間データを生成した状態になっています。カレンダーコンポーネントから期間を変更したとき、かなりの速さでダッシュボードが更新されることを体感できるのではないかと思います。
なお、中間データはリアルタイムのデータではなく、日次で事前に集計されたデータを一時的に保管しておくテーブルとなっています。日時以外にも週次・月次といった任意のタイミングで、中間データの中身を入れ替えることが可能です。
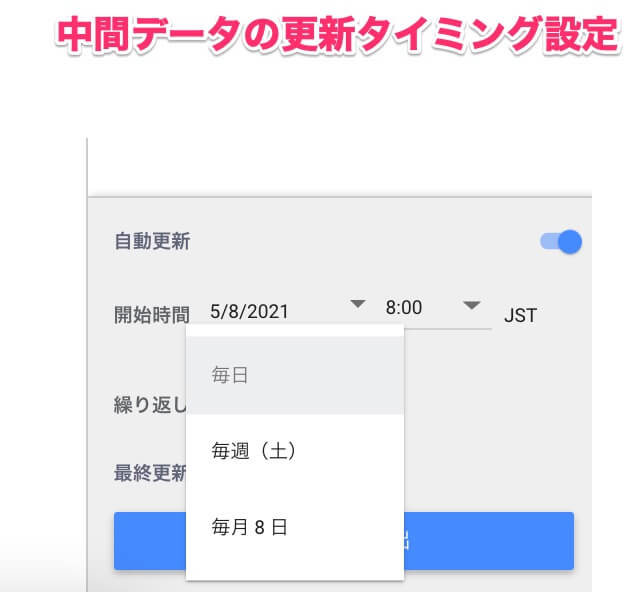
中間データの更新条件を入れると前日以前のデータが対象となるため、リアルタイム性は失われます。ただ、週次・月次データの評価であれば問題ないと思います。
「データの抽出」機能を利用する
では、実際に「データの抽出」機能を利用してみましょう。データの抽出には、あらかじめ「データベースへの接続用データソース」と「集計用の関数」を用意しておく必要があります。その後の操作も順を追って見ていきます。
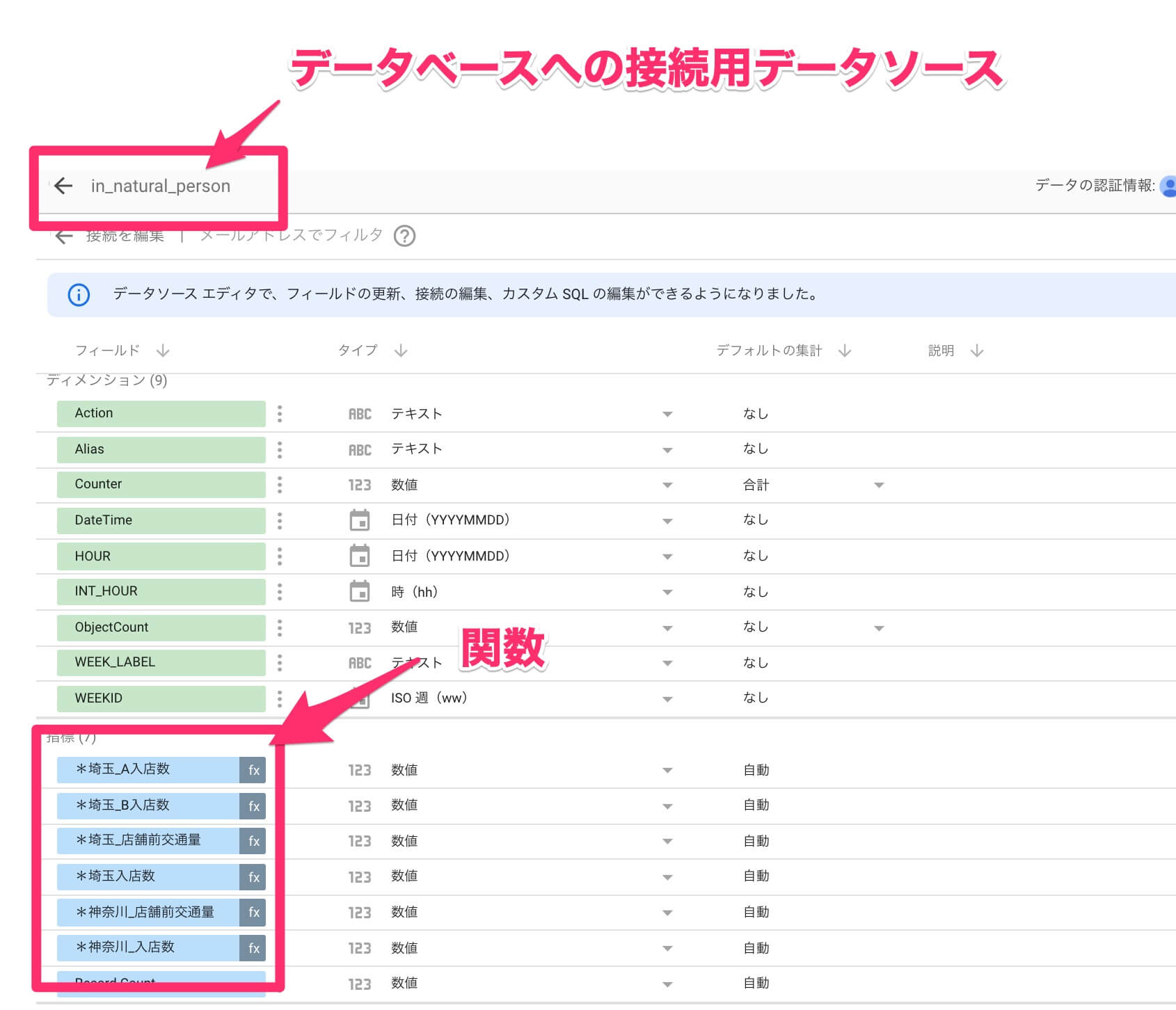
データベースへの接続用データソースといっても、スプレッドシートなどと同様の、通常のデータソースです。その中で関数(条件設定)も実装しておきます。
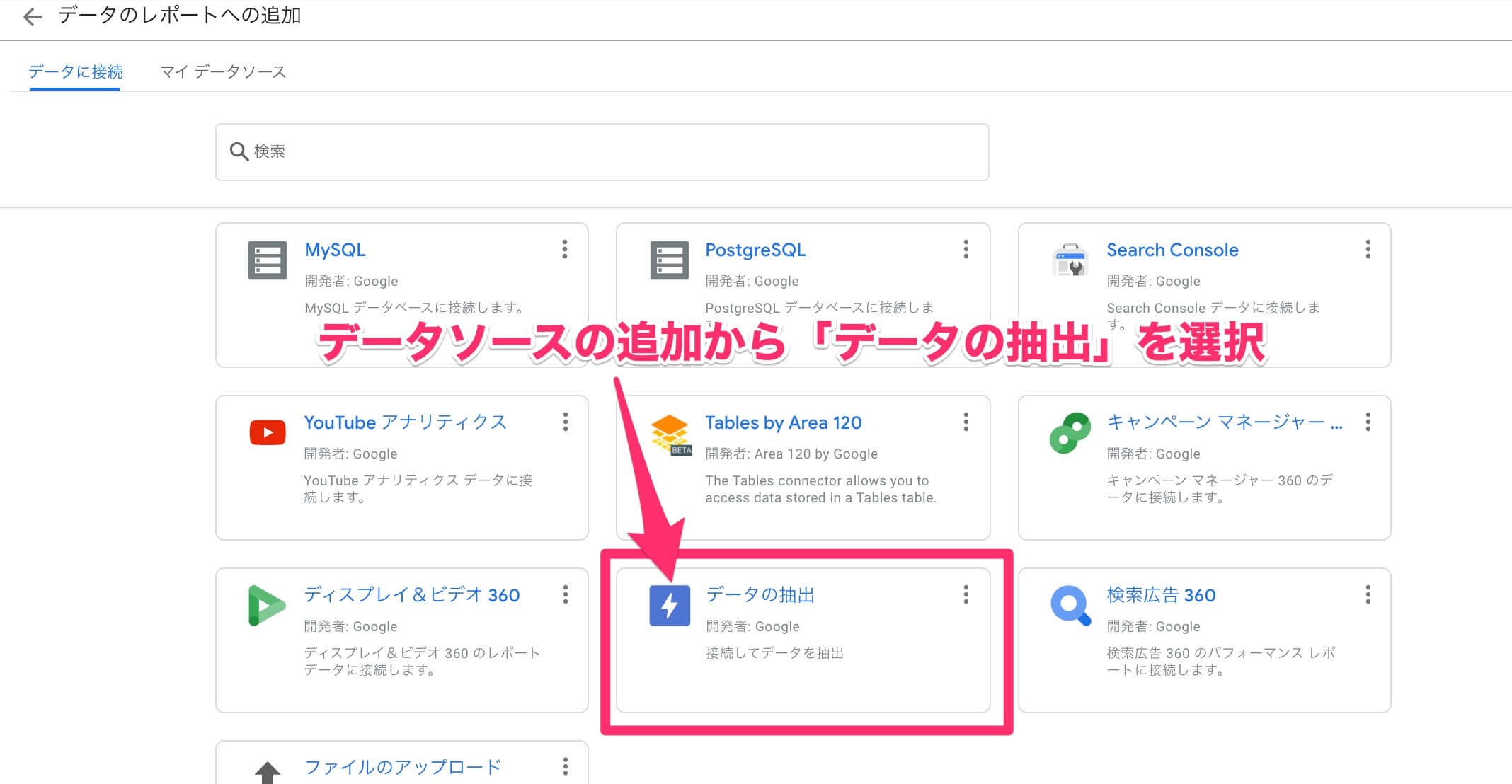
データポータルの画面上から[データソースの追加]を選択し、[データの抽出]を選択します。
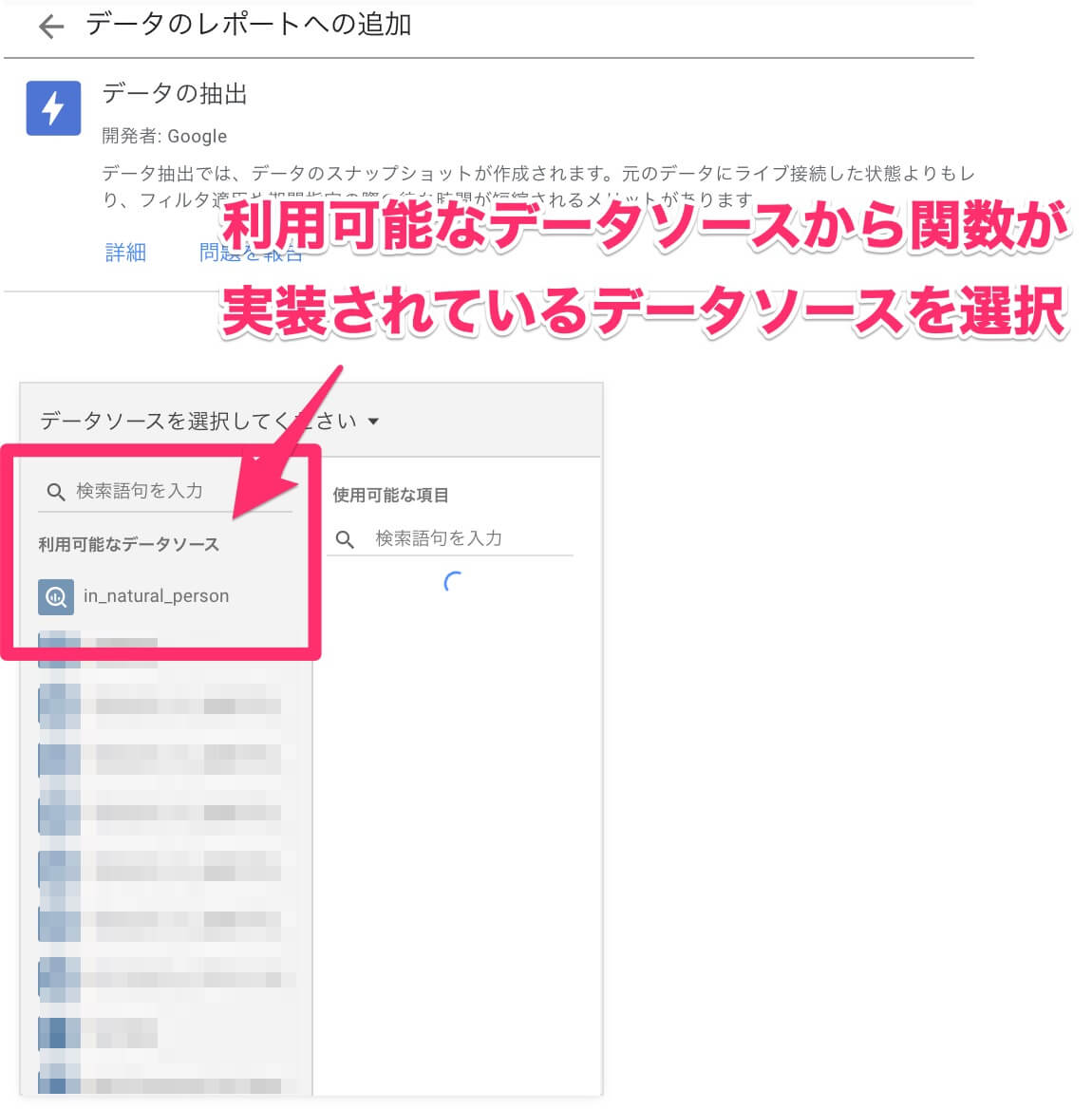
設定画面に切り替わると、[利用可能なデータソース]の一覧が表示されます。ここでは[in_natural_person]というBigQueryに接続しているデータソースを選択します。
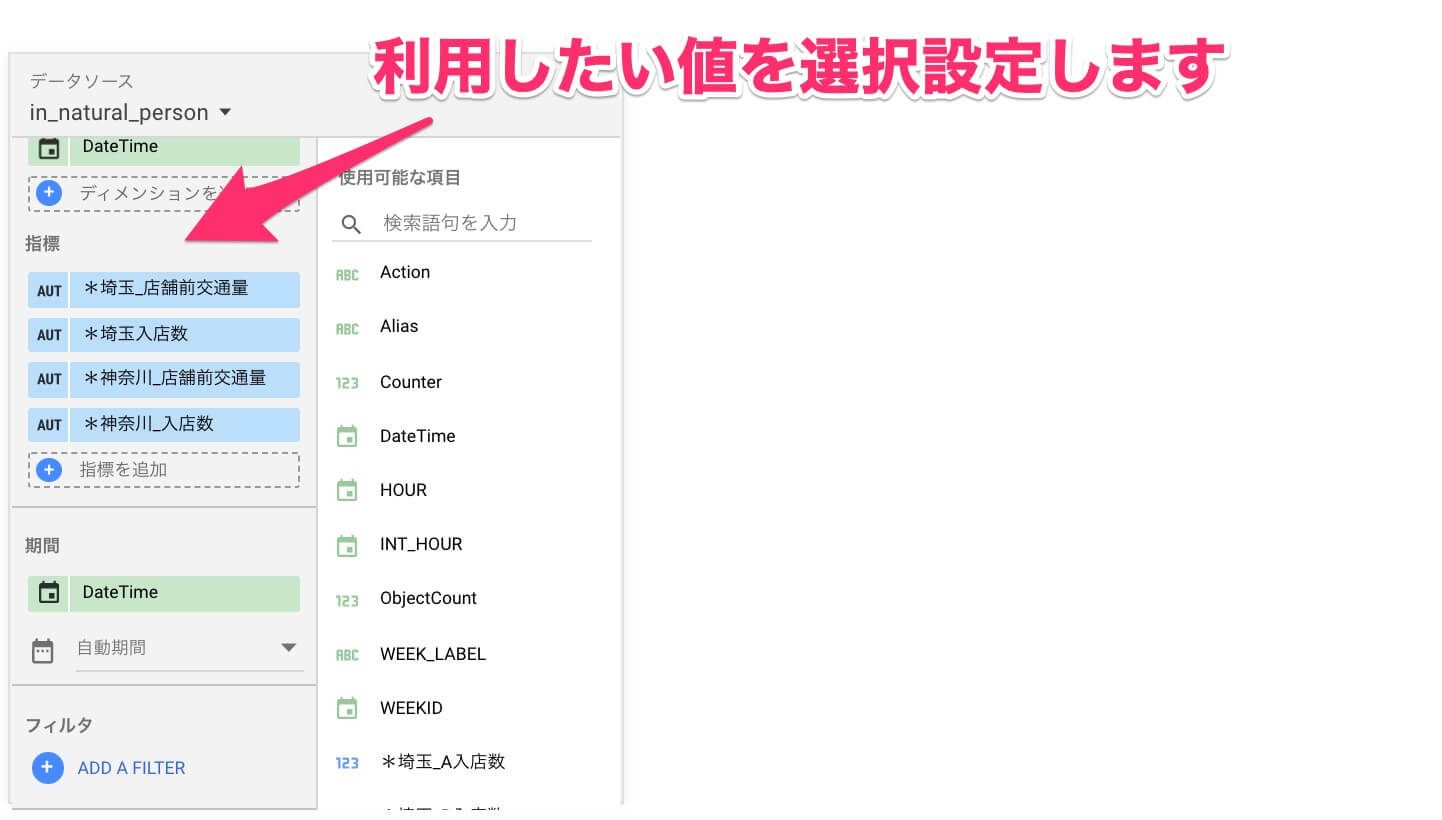
データソースを選択すると、データソース内の指標・関数が選択できるので、抽出したい指標・関数を選択設定します。ここでフィルター機能を使って条件設定しておくことで、抽出時に不要な条件を除外して抽出をしてくれるため、中間データの容量を軽減させることができます。
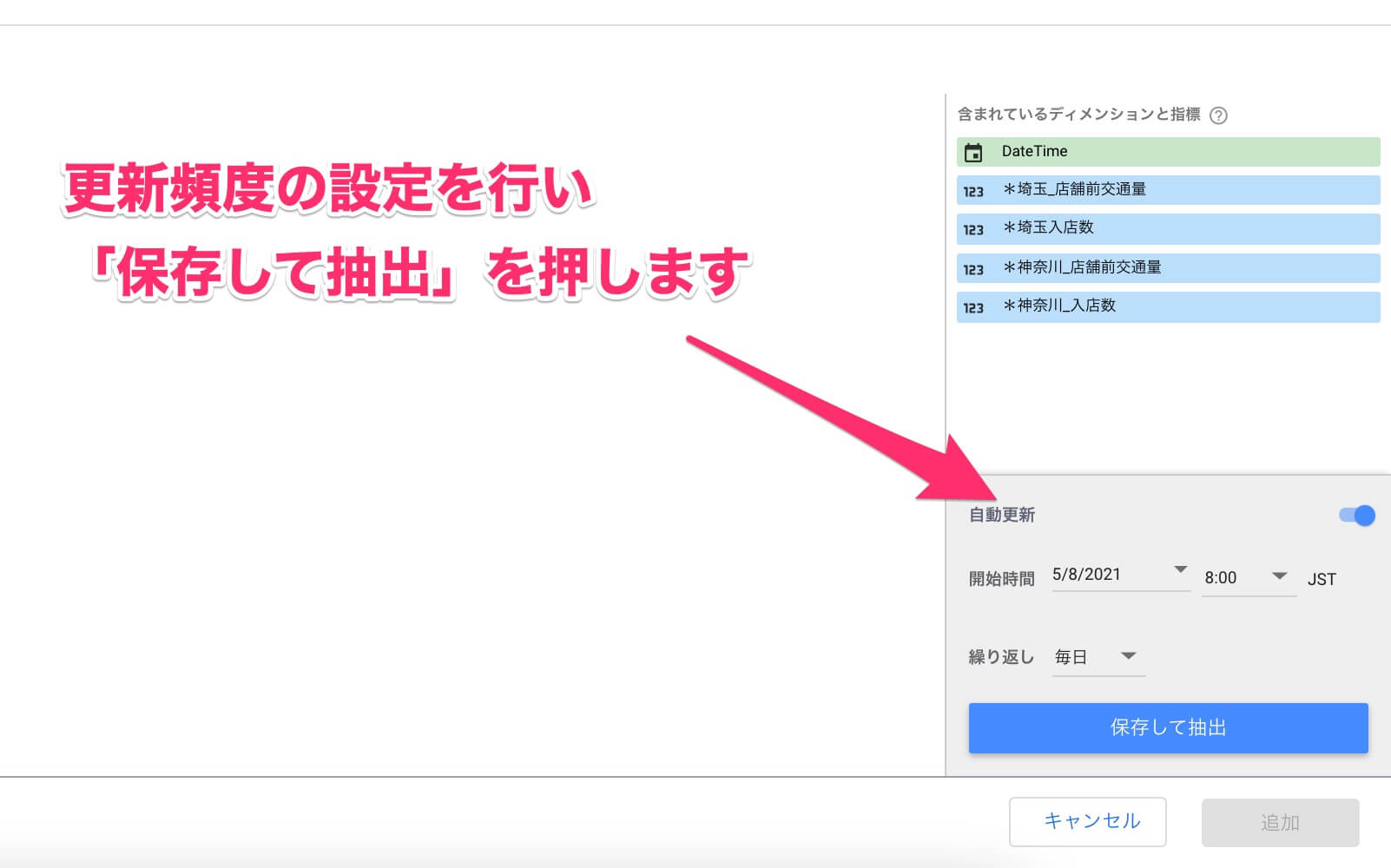
設定が済んだら、画面右下の[自動更新]にあるスイッチをオンにすることで、任意のタイミングで抽出データを更新する設定ができます。[保存して抽出]をクリックすると、データの抽出処理が実行されます。なお、1回だけの利用であれば、自動更新をさせない設定にもできます。
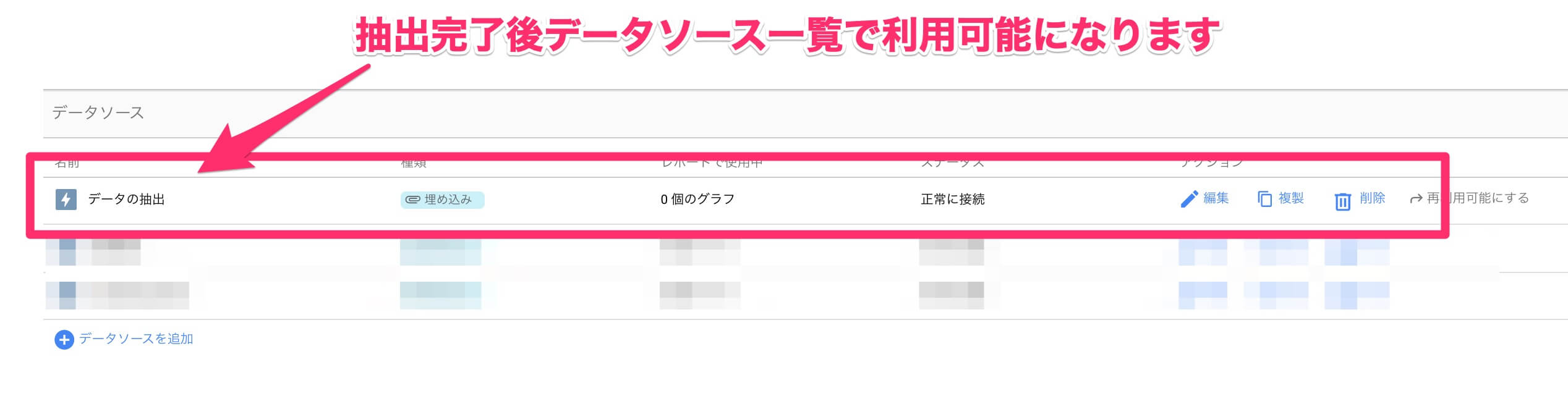
[保存して抽出]をクリックしたからしばらくすると、データソースに[データの抽出]として登録されます。画面反映にタイムラグがあるときがあるので、表示されない場合は画面をリロードしてみてください。
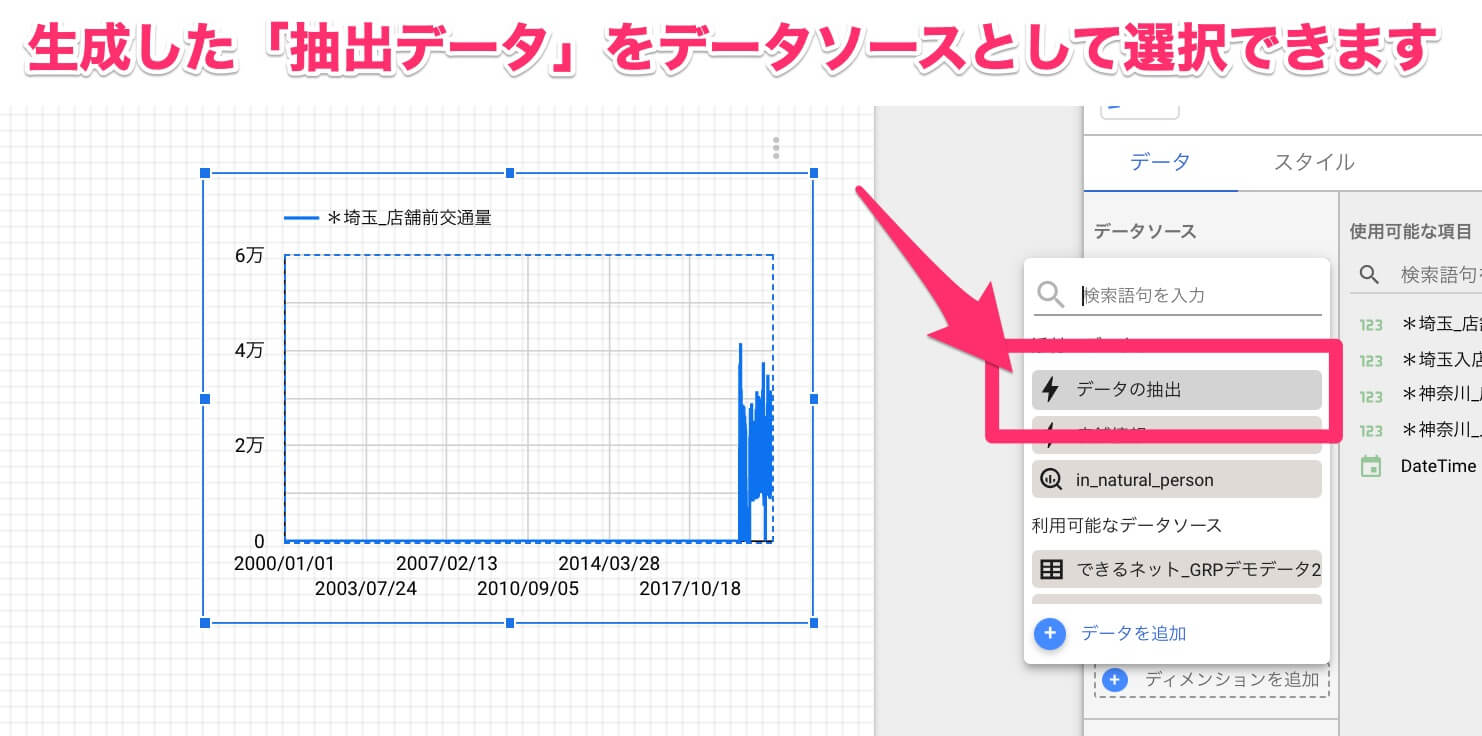
抽出が完了すると、グラフ作成画面でのデータソースの選択が可能になります。あとは通常通り、指標を選択すればグラフに表示されます。
快適性を高めて活用されるダッシュボードに
DXでもっとも重要なことは、社内の人がデータを触る習慣(理由)を作り、「データを運用に乗せる」ことです。しかし、それが難しいのも事実で、さまざまな書籍などでも使ってもらうまでの苦労話が語られています。
筆者の場合も、やはり「面倒くさい」「分からない」「欲しい情報がない」「重い」といった感情的な理由から、なかなか会議がダッシュボードを基点に進行せず、もどかしさを感じる時期がありました。
しかし、1人ひとりの感覚的な評価指標を細かくヒアリングして関数化し、インタクションの部品を配置しつつ、肥大化したデータ量をデータの抽出によって軽量化してようやく、「使える」ダッシュボードができたという感覚があります。
ダッシュボードは一度作って完成することはなく、毎週のようにどこかを改修し、複雑な集計作業を自動化していく効果は明らかにあると思います。やりたがらない人たちの言い訳を潰していくことで、DXは実現できるといってもいいでしょう。
ちなみに、今回解説したデータの抽出という作業は、本来は「ETL」(Extract, Load, Transform)もしくは「ELT」という領域の話になります。また、RPA(Robotic Process Automation)によるデータの自動加工という高度な情報処理の話とも関連するのですが、データポータルでは、そういった難しい話を抜きに実装が可能です。
すでに実装済みのデータソースをそのまま流用することもできるため、移行も非常に簡単です。ぜひ試してみてください。


